Performance optimization in Go: Checkmate Performance using Chess Piece Movements as an example
In the vast realm of programming challenges, few tasks merge elegance and complexity as seamlessly as crafting an efficient algorithm for…
In the vast realm of programming challenges, few tasks merge elegance and complexity as seamlessly as crafting an efficient algorithm for…
Performance optimization in Go: Checkmate Performance using Chess Piece Movements as an example
In the vast realm of programming challenges, few tasks merge elegance and complexity as seamlessly as crafting an efficient algorithm for chess piece movements. From the Pawn’s humble stride to the Queen’s sweeping dominance, modelling their possibilities is a dance of logic and optimization. This journey through chess computation isn’t just about achieving functional correctness — it’s about reimagining performance.
This blog chronicles my six-version journey in optimising chess piece movements, demonstrating the evolution of code, the pitfalls of early approaches, and the triumph of refined strategies.
v0.0.1 : The Beginning
The journey began with version 0.0.1, a humble yet functional implementation. Each chess piece’s movements were calculated using straightforward logic, focusing solely on functionality. While the program worked, it lacked modularity and scalability, characteristics crucial for a robust solution. Performance benchmarks were respectable for a first attempt.
goos: darwin
goarch: arm64
pkg: github.com/asahasrabuddhe/chess
cpu: Apple M1 Max
BenchmarkPawn_Moves-12 29405866 40.82 ns/op 18 B/op 2 allocs/op
BenchmarkKing_Moves-12 5649428 207.7 ns/op 144 B/op 9 allocs/op
BenchmarkQueen_Moves-12 1598154 742.8 ns/op 502 B/op 28 allocs/op
BenchmarkPosition_String-12 56797339 21.09 ns/op 2 B/op 1 allocs/op
The limitations of this approach soon became evident when envisioning scalability or further optimizations.
v0.0.2: A Fork in the Road
With version 0.0.2, the focus shifted to consolidating movement logic, aiming to make the codebase modular and more readable. This approach simplified the definition of moves by allowing reusable components to define movements across pieces. While this improved the code’s elegance and structure, the impact on performance was stark. Execution times for move calculations ballooned — Pawn became 295% slower, King 293% slower, and Queen moves saw a dramatic 1751% increase in execution time. While allocation efficiency improved significantly, particularly for the Queen (reducing allocations by 78.6%), the regressions in execution time and inconsistent memory usage highlighted the cost of prioritising readability over raw performance.
goos: darwin
goarch: arm64
pkg: github.com/asahasrabuddhe/chess
cpu: Apple M1 Max
| Benchmark | benchmarks/v0.0.1.txt (sec/op) | benchmarks/v0.0.2.txt (sec/op) | vs base |
|---|---|---|---|
| Pawn_Moves-12 | 40.69n ± 0% | 160.75n ± 1% | +295.06% (p=0.000 n=10) |
| King_Moves-12 | 207.6n ± 48% | 817.4n ± 2% | +293.83% (p=0.000 n=10) |
| Queen_Moves-12 | 766.7n ± 3% | 14191.5n ± 1% | +1751.11% (p=0.000 n=10) |
| Position_String-12 | 21.31n ± 1% | 21.35n ± 5% | ~ (p=0.209 n=10) |
| geomean | 108.4n | 446.7n | +312.15% |
| Benchmark | benchmarks/v0.0.1.txt (B/op) | benchmarks/v0.0.2.txt (B/op) | vs base |
|---|---|---|---|
| Pawn_Moves-12 | 18.00 ± 0% | 16.00 ± 0% | -11.11% (p=0.000 n=10) |
| King_Moves-12 | 144.0 ± 0% | 240.0 ± 0% | +66.67% (p=0.000 n=10) |
| Queen_Moves-12 | 502.0 ± 0% | 1008.0 ± 0% | +100.80% (p=0.000 n=10) |
| Position_String-12 | 2.000 ± 0% | 2.000 ± 0% | ~ (p=1.000 n=10) ¹ |
| geomean | 40.16 | 52.75 | +31.33% |
¹ all samples are equal
| Benchmark | benchmarks/v0.0.1.txt (allocs/op) | benchmarks/v0.0.2.txt (allocs/op) | vs base |
|---|---|---|---|
| Pawn_Moves-12 | 2.000 ± 0% | 1.000 ± 0% | -50.00% (p=0.000 n=10) |
| King_Moves-12 | 9.000 ± 0% | 4.000 ± 0% | -55.56% (p=0.000 n=10) |
| Queen_Moves-12 | 28.000 ± 0% | 6.000 ± 0% | -78.57% (p=0.000 n=10) |
| Position_String-12 | 1.000 ± 0% | 1.000 ± 0% | ~ (p=1.000 n=10) ¹ |
| geomean | 4.738 | 2.213 | -53.29% |
¹ all samples are equal
v0.0.3 & v0.0.4: Breaking New Ground
In v0.0.3, the focus shifted to refining the code by eliminating unused sections and enhancing readability through better comments. Benchmarking revealed that runtime.duffcopy, a low-level Go runtime function optimized for bulk memory copying, was a significant source of execution time overhead. This function, inspired by Duff's Device—a loop unrolling technique designed to optimize data copying by reducing loop iteration overhead—became a bottleneck due to inefficiencies in how movement data was being handled. When performing tasks such as copying slices, assigning large structs, or using functions like copy, the Go runtime leverages runtime.duffcopy to manage these operations efficiently, but in this case, it was contributing to performance issues.
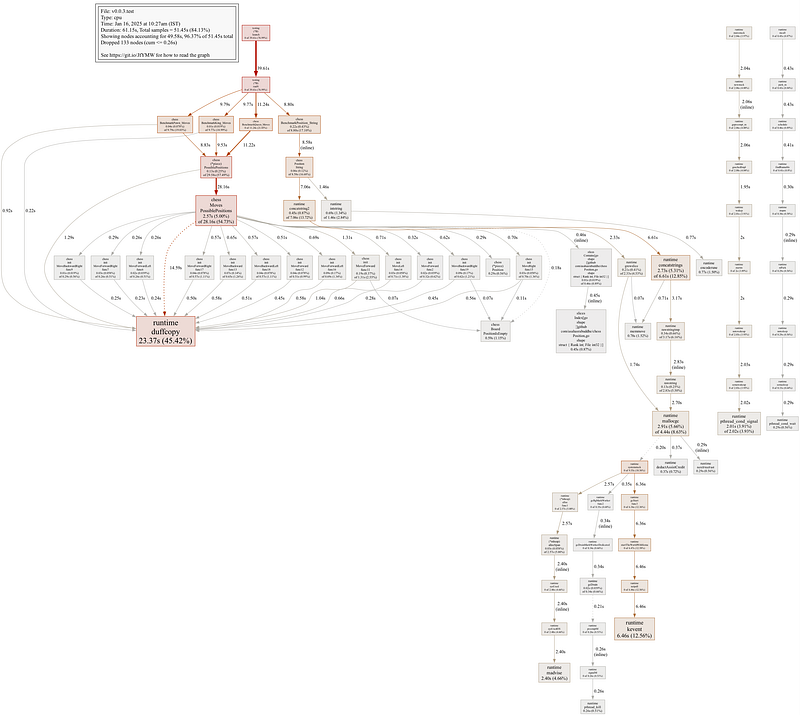
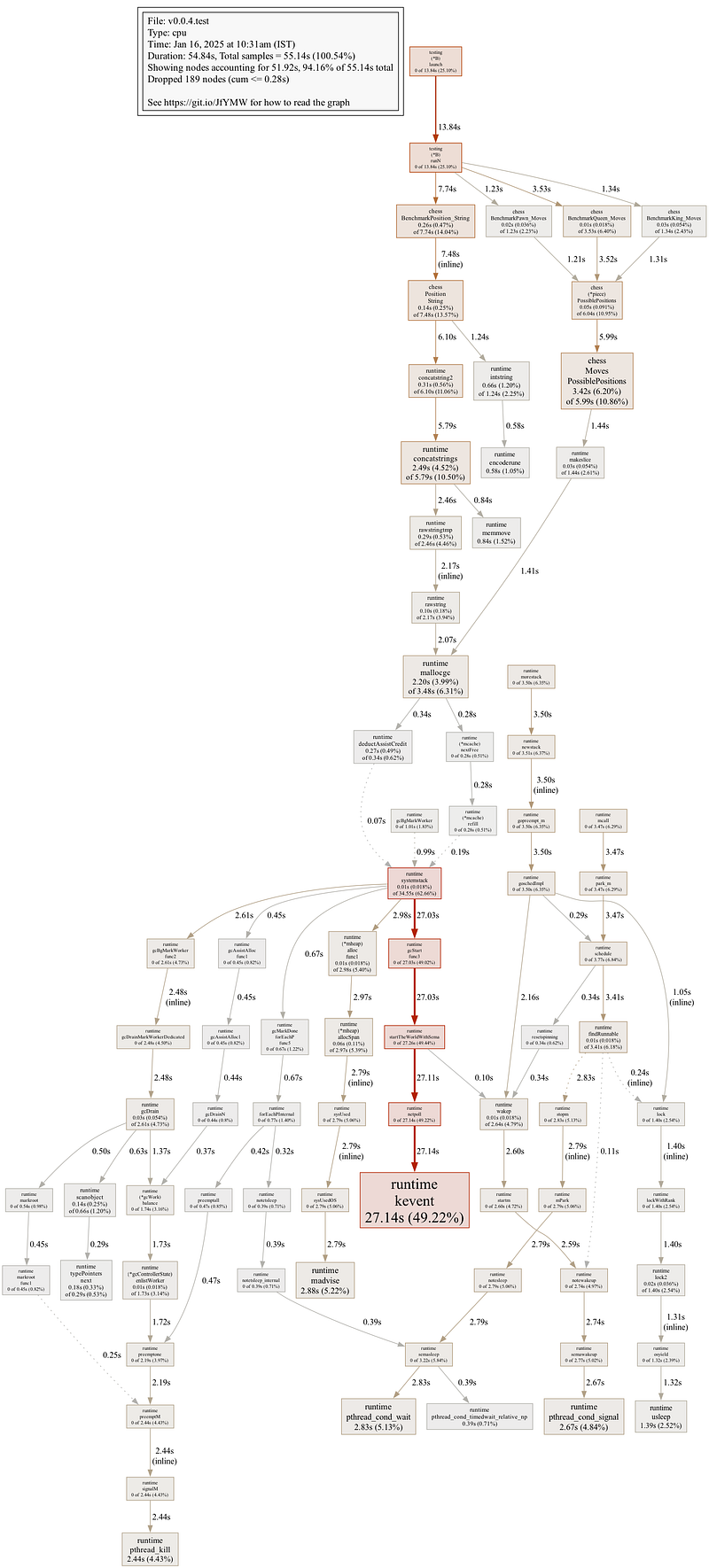
Recognising this, version 0.0.4 introduced several key changes to address the issue. The MoveFunc was optimized to avoid unnecessary duplication of the Position struct, thereby reducing reliance on runtime.duffcopy. Redundant checks like PositionIsEmpty were removed, further streamlining the logic. Additionally, concurrency was introduced to parallelise the generation of move sets, leveraging Go’s strengths to significant effect. Finally, pre-allocating the slice for storing possible positions minimised runtime overhead.
goos: darwin
goarch: arm64
pkg: github.com/asahasrabuddhe/chess
cpu: Apple M1 Max
| Benchmark | benchmarks/v0.0.3.txt (sec/op) | benchmarks/v0.0.4.txt (sec/op) | vs base |
|---|---|---|---|
| King_Moves-12 | 797.50n ± 1% | 93.53n ± 2% | -88.27% (p=0.000 n=10) |
| Pawn_Moves-12 | 159.40n ± 3% | 34.58n ± 1% | -78.31% (p=0.000 n=10) |
| Position_String-12 | 21.51n ± 2% | 21.88n ± 1% | +1.74% (p=0.015 n=10) |
| Queen_Moves-12 | 14254.5n ± 6% | 380.1n ± 15% | -97.33% (p=0.000 n=10) |
| geomean | 444.3n | 72.02n | -83.79% |
| Benchmark | benchmarks/v0.0.3.txt (B/op) | benchmarks/v0.0.4.txt (B/op) | vs base |
|---|---|---|---|
| King_Moves-12 | 240.0 ± 0% | 128.0 ± 0% | -46.67% (p=0.000 n=10) |
| Pawn_Moves-12 | 16.00 ± 0% | 64.00 ± 0% | +300.00% (p=0.000 n=10) |
| Position_String-12 | 2.000 ± 0% | 2.000 ± 0% | ~ (p=1.000 n=10) ¹ |
| Queen_Moves-12 | 1008.0 ± 0% | 448.0 ± 0% | -55.56% (p=0.000 n=10) |
| geomean | 52.75 | 52.05 | -1.32% |
¹ all samples are equal
| Benchmark | benchmarks/v0.0.3.txt (allocs/op) | benchmarks/v0.0.4.txt (allocs/op) | vs base |
|---|---|---|---|
| King_Moves-12 | 4.000 ± 0% | 1.000 ± 0% | -75.00% (p=0.000 n=10) |
| Pawn_Moves-12 | 1.000 ± 0% | 1.000 ± 0% | ~ (p=1.000 n=10) ¹ |
| Position_String-12 | 1.000 ± 0% | 1.000 ± 0% | ~ (p=1.000 n=10) ¹ |
| Queen_Moves-12 | 6.000 ± 0% | 1.000 ± 0% | -83.33% (p=0.000 n=10) |
| geomean | 2.213 | 1.000 | -54.82% |
¹ all samples are equal
These changes delivered dramatic performance improvements. Execution times for the King, Pawn, and Queen moves dropped by 88.27%, 78.31%, and 97.33%, respectively. Memory consumption also decreased substantially, particularly for the King and Queen, whose memory usage reduced by 46.67% and 55.6%, respectively. Allocation efficiency was further enhanced, with the King and Queen moves requiring 75% and 83.3% fewer allocations. Addressing the bottleneck caused by runtime.duffcopy was pivotal in achieving these gains.
v0.0.5: Fine-Tuning with Precision
The final iteration, version 0.0.5, focused on optimising the String() method for the Position struct. This method, responsible for converting a position on the chessboard into its string representation (e.g., "A1" or "H8"), was initially implemented using concatenation:
return string('A'+p.File) + string('8'-rune(p.Rank))In this approach, string('A'+p.File) and string('8'-rune(p.Rank)) each create temporary strings, requiring separate memory allocations. The concatenation using the + operator then results in a third allocation to combine these strings into the final result. This process involves multiple allocations and copying operations, which not only adds CPU overhead but also creates short-lived objects that increase the workload for the garbage collector.
To address these inefficiencies, the String() method was reimplemented using a pre-allocated byte slice:
buf := []byte{
byte('A' + p.File),
byte('8' - p.Rank),
}
return string(buf)In this revised implementation, the byte slice buf is pre-allocated with the exact size needed for the final string. Both characters are assigned directly into the slice, avoiding intermediate allocations. The final string is then created in a single operation by converting the byte slice to a string. This approach eliminates redundant memory allocations and reduces copying overhead.
Impact: This optimization resulted in a 56.8% reduction in execution time for the String() method. By avoiding multiple short-lived allocations, it also minimised garbage collection activity, further improving runtime performance. The efficiency gained from this small yet targeted change underscores the importance of scrutinising frequently used methods for potential bottlenecks.
This change exemplified how micro-optimisations — when applied to high-frequency operations — can yield significant performance gains, demonstrating the value of understanding and addressing low-level inefficiencies in critical code paths.
This journey through six versions of chess piece movement logic in Go highlighted several critical lessons. Optimization is an iterative process that requires balancing performance, readability, and modularity. Regular benchmarking is essential, as it provides data-driven insights to guide meaningful improvements. Finally, leveraging Go’s concurrency model can unlock dramatic gains, particularly for computationally intensive tasks.
Optimising chess piece movements in Go was more than a technical challenge — it was a lesson in balancing creativity with discipline. Each iteration brought me closer to a solution that combined the precision of a perfectly executed chess match with the strategy of thoughtful problem-solving. Whether you’re a chess enthusiast, a Go developer, or both, this journey showcases the beauty of innovation through code. The only question left: what will be your next move?